오랜만에 블로그를 다시 잡아보는데요,
앞으로 다룰 주제는 제가 현재 졸업작품으로 다루고 있는 인공지능 작곡기(정확히는 편곡기)에 대해서 설명할 예정입니다.
오늘은 가장 기본이 되는 주제를 다룰 것은 아니고, 부수적으로 필요한 기본 개념들을 먼저 정리했습니다.
큰 주제는 조금 더 정리해서 올릴 예정입니다.
순서대로 정리하고 싶은 마음 반, 이미 정리된 것들을 먼저 올리고 싶은 마음 반이여서 고민을 했는데,
하고 싶은걸 먼저해야 계속해서 블로그를 할 수 있을 것 같아서 오늘은 간단하게 전에 정리했던 내용을 올리려고 합니다.
처음에 이 인공지능 작곡기를 계획하면서, midi 파서를 VAE, DAE기법으로 인디코딩시키려고 했습니다만,
생각보다 듣기 좋은 음악이 나올 것 같지가 않아서 Resnet과 cycleGAN을 이용하는 쪽으로 회선 시켰습니다.
그렇기에 오늘은 VAE와 GAN의 간단한 차이점을 적어보려고 합니다.

VAE는?
- Variational Auto-Encoder
- 복잡한 데이터 생성 모델을 설계하고 대규모 set에 적응 할 수 있게 해줌
- input data를 잠재변수 z로 encoding 한 후, 스스로 input을 복원해 내는 방법
- VAE에서의 Loss functoion은 input x와 복원된 x'(decoding 된 x) 간의 Loss로 정의
- VAE에서는 Auto-Encoder가 input을 따라 그리는 것에만 맞게 학습 시킴
- 결론적으로 z는 의미론적이지 않음
GAN은?
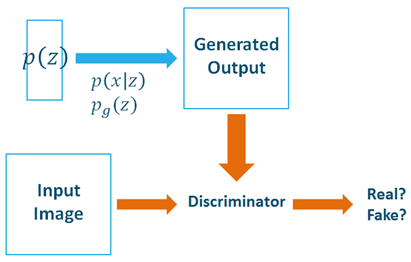
- Generative Adversarial Nets
- Generator과 Discriminator가 서로 대립하여 서로의 성능을 점차 개선해 나가는 개념
- ex) 지폐위조범(Generator)은 경찰(Discriminator)을 최대한 열심히 속이기 위해 노력함
경찰은 지폐위조범의 위조된 지폐를 감별하기 위해(Classify) 노력함
이런 경쟁 속에서 두 그룹 모두 속이는 능력, 구별하는 능력이 발전하게 됨
= 결과적으로, 진짜 지폐와 위조 지폐를 구별할 수 없을 정도에 이름
- Generative model G -> data x의 distibution을 알아내려고 노력
(G가 data distribution을 모사할 수 있으면 sample과 data를 구별할 수 있다.)
- Discriminator model D -> sample이 training data인지, G가 만들어낸 data 인지 구별하여 각각의 확률을 estimate시킴
결론적으로 VAE와 GAN의 차이점은?
GAN
-generator model의 목적 자체가 어떤 data의 분포를 학습하는 것이 아님
- 진짜 같은 sample을 generate하는 것이 목적
VAE
- data의 분포를 학습하고 싶은데, 이 data가 다루기 힘들기 때문에 variational inference(변화 추론)하는 방법
- VAE는 data 분포가 잘 학습되기만 하면 sampling (=data generation)이 저절로 따라옴
'IT > GAN' 카테고리의 다른 글
| Latent space 간단 정리 (0) | 2019.08.03 |
|---|---|
| Mode collapse 아주 간단 정리 (0) | 2019.08.03 |
| Regularization & Norm 간단 정리 (0) | 2019.07.04 |


