오늘은 CNN, ML 알고리즘에서 많이 보이는 Norm에 대해 간단히 정리하려고 합니다.
일반적으로 Deep Learning에서 network의 Overfitting(과적합) 문제를 해결하는 방법으로 3가지 방법을 제시합니다.
1. 더 많은 data를 사용
2. Cross validation
3. Regularization
|
*2번의 cross validation(교차 검증) - 모든 데이터가 최소 한 번은 test set으로 사용하도록 함 - Training set과 Test set을 분리하여 training set에서 모델의 계수를 추정한 후, test set으로 성능을 평가
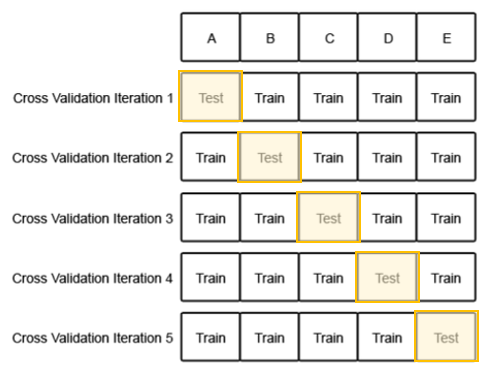 test set을 어떻게 잡느냐에 따라 성능이 아주 상이하게 나올 경우 우연으로 모델 평가 지표에 편향이 생기게 됨 cross validiation은 모든 data를 test set으로 사용하기 때문에 편향을 줄일 수 있음
장점 - 총 데이터 갯수가 적은 data set에서 정확도 향상 가능 (데이터 추가하지 않고 overfitting 해결 가능)
|
다시 돌아와서, 더 이상 data 추가가 어렵거나, 학습 data를 늘려도 overfitting 문제가 해결되지 않을 때
3번 Regularization을 사용합니다. 이 Regularization은 lose function을 변형시켜 사용합니다.
Regularization(정규화)
- Regulaization을 통해 특정 값을 가지는 outlier의 영향을 적게 받도록 하여 일반화에 적합한 특성을 갖게 만드는 것
- Regularization은 L1과 L2로 나뉨
• L1 Regularization

- L1 Regularization은 1차항
- C0: 원래의 cost function
- n: training data의 개수
- λ: regularization 변수
- w: weight
- w에 대해서 편미분 수행 시

- 상수 값을 빼기 때문에 작은 가중치들은 거의 0으로 수렴 (몇 개의 중요한 가중치만 남음)
- 몇 개의 의미 있는 값을 내고 싶을 때에 효과적
• L2 Regularization

- 학습의 방향을 단순히 C0값이 작아지는 방향으로만 진행시키는 것이 아니라 w값 역시 최소로 작아지는 방향으로 진행
- 새롭게 정의된 cost function을 가중치 w에 대해 편미분 수행 시

- 특정 가중치가 비 이상적으로 커지고, 학습 효과에 큰 영향을 끼치는 것을 방지할 수 있음
NORM
norm이란?
- 수학적으로 벡터 공간 또는 행렬에 있는 모든 벡터의 전체 크기
- 단순화를 위해 표준이 높을수록 행렬 또는 벡터의 값이 커짐

p: norm의 차수 (p의 차수에 따라 L0, L1, L2결정)
n: 대상 벡터의 요소 수
• L0 Norm
- 실제로는 norm이 아님
- 벡터의 0이 아닌 요소의 총 수에 해당
- ex) v(0,0), v(0,2)의 L0 norm의 개수: 1개 (0이 아닌 요소가 1개뿐이기 때문)

• L1 Norm

- Manhattan Distance 또는 Taxicab norm으로 많이 알려짐
- 벡터의 요소에 대한 절대 값
- 벡터 사이의 거리를 측정
- 벡터의 모든 구성 요소에 동일한 가중치가 적용됨
- L1 Regularization, computer vision 영역에서 사용

- 출발지(0,0)에서 목적지(3,4)에 도착하기 위해 블록 사이를 여행하며 거리를 측정하는 방식
- vector X = [3,4] = 7
• L2 Norm

- Euclidean norm이라고도 알려진 가장 일반적인 Norm
- 한 지점에서 다른 지점으로 갈 때의 가장 짧은 거리를 측정

- L2 Norm은 가장 직접적인 경로
- L2 Regularization, KNN알고리즘, K-means 알고리즘에서 사용
- *고려할 점: 벡터의 각 구성 요소가 제곱이 되어있기 때문에 결과 값의 왜곡 가능성이 있음
• L - Infinity Norm
- 벡터 요소 중 가장 큰 크기를 제공
- vector X = [-6,4,2] 일 때, L - Infinity Norm = 6
- 가장 큰 요소만 효과가 있음
- Color pixel에서 R, G, B 최대 차이 계산에 사용
• Maximum Norm
- p값을 무한대로 보냈을 때의 norm
- 벡터 성분의 최댓값

'IT > GAN' 카테고리의 다른 글
| Latent space 간단 정리 (0) | 2019.08.03 |
|---|---|
| Mode collapse 아주 간단 정리 (0) | 2019.08.03 |
| VAE & GAN 간단 비교 (0) | 2019.06.28 |


